
Building Simple And Powerful AI Assistant For AWS Docs
Leveraging RAG, MCPs and Amazon Nova LLMs for Efficient AWS Documentation Queries

Working with AWS on a daily basis means diving into the documentation often. It is great, well written. But navigating its sheer volume to pinpoint exactly what you need, when you need it, can take a bit of time sometimes.
There are LLMs. RAG is well-known. MCP servers seem pretty interesting. So I got an idea - can I create an AI-powered assistant that can help me quickly query the docs and see what’s up? Yes!
Also, while I’m at that - it’s a good opportunity to test Amazon Nova LLMs (Micro, Lite and Pro).
This article walks through the creation of lumen, a proof-of-concept app I built to help with AWS-related questions, by combining Retrieval Augmented Generation (RAG), AWS Model Context Protocol (MCP) servers, and the capabilities of Amazon's Nova Large Language Models (LLMs).
Architecture Overview
We covered the why part. Let’s now focus on the what and how parts.
Here is a quick diagram of lumen:

It has what the vast majority of RAG systems have these days:
Knowledge Base - Qdrant Vector DB
Retriever - LangChain’s tool in Python BE
Integration Layer - LangChain/LangGraph
Generator - Amazon Nova LLMs
There is one more thing I added - AWS MCP Servers:
Core MCP Server
AWS Documentation MCP Server
Retrieval Augmented Generation (RAG)
lumen ingests the PDF files. PDF is one of the few file formats that proves to be a challenge to parse and chunk time and time again. No parsing tool is perfect, but the two I found to work best with the AWS Docs PDFs are Docling and PyMuPDF4LLM.

How does the file ingestion work?
Get the AWS Docs PDF file
Uploaded by the user
Downloaded by the app if a user submits online PDF location
Optimization
Remove Table of Contents, Document revision and similar sections as they do not provide much value in terms of aiding the LLM response. But they do help in the next steps!
Parsing
This is the most important part. PDF file is parsed and converted to Markdown. Takes the most time too.
Chunking
Markdown shines here. Each document is chunked based on the heading levels in small, byte-sized pieces. This process will make each embedding more relevant and on point.
Generating Vectors
The final part. This is where embeddings are created using Amazon Titan Text Embeddings V2 model and then stored in Qdrant Vector DB.

Why Amazon Titan Text Embeddings V2 model?
With a maximum of 8192 input text tokens it can embed larger documents or text chunks without needing too much splitting (this can provide more contextual information)
Flexible output dimensions (1024, 512, 256) allow fine-tuning the trade-off between embedding context and performance
More than 100 supported languages in preview means you don’t really have to think about supporting multiple languages (but test the system always!)
It makes things easier if you are already invested in the AWS ecosystem by being available in the Bedrock service as a first-party model
How does the data retrieval work?
Embed user query
Send user message to the embedding model
Search the Qdrant Vector DB
Use the calculated vector to search Qdrant Collection
Return the content with metadata
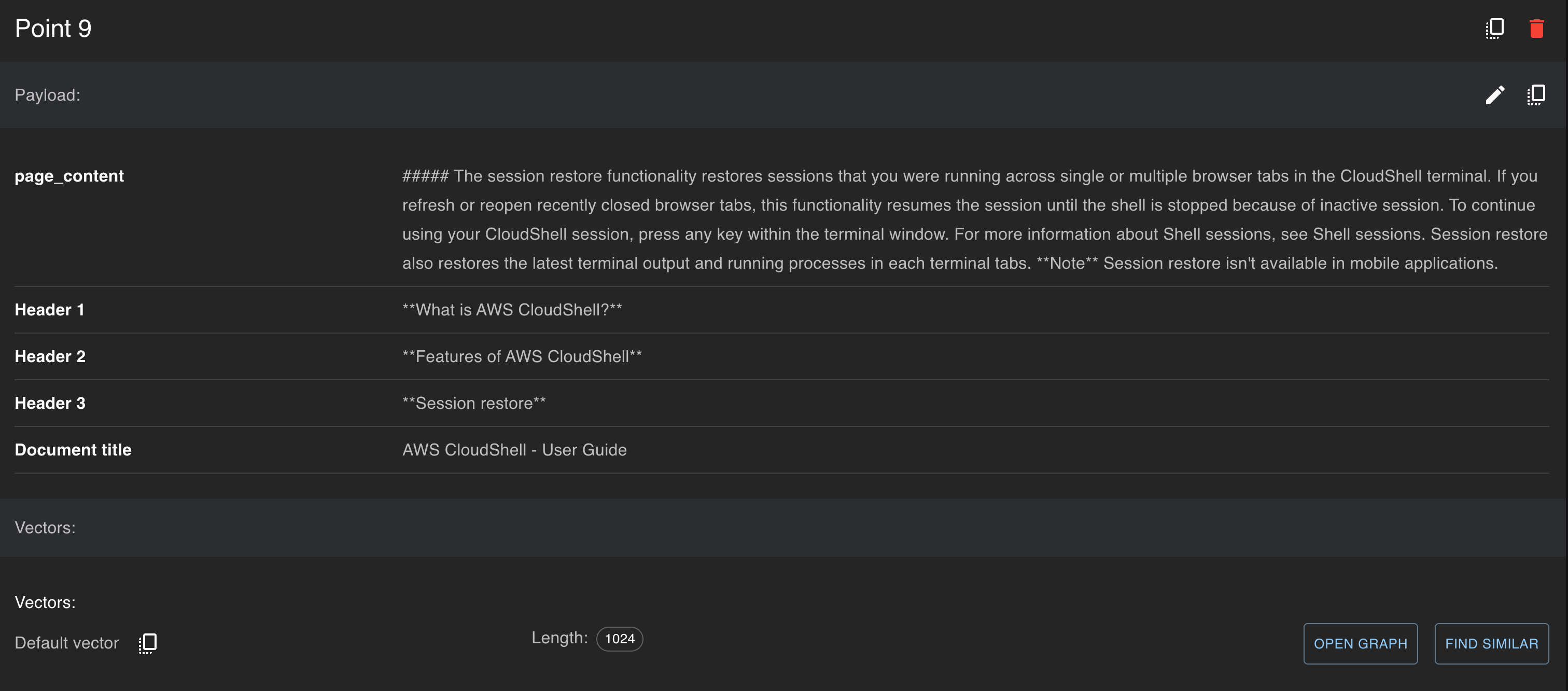
Remember that the documents are chunked based on the heading levels? Metadata contains heading levels and document title:

Send the results to the LLM
The final step that provides precise and factual data which helps LLM to create a better response
You can use the search page to check the data retrieval:

Model Context Protocol (MCP) Servers
lumen also supports AWS MCP Servers, namely the Core and AWS Documentation ones.

Core MCP Server
MCP server that provides a starting point for using the following awslabs MCP servers - awslabs.cdk-mcp-server - awslabs.bedrock-kb-retrieval-mcp-server - awslabs.nova-canvas-mcp-server - awslabs.cost-analysis-mcp-server - awslabs.aws-documentation-mcp-server - awslabs.aws-diagram-mcp-server
- AWS MCP Servers Docs - Direct Link -
AWS Documentation MCP Server
Model Context Protocol (MCP) server for AWS Documentation
This MCP server provides tools to access AWS documentation, search for content, and get recommendations.
- AWS MCP Servers Docs - Direct Link -
I integrated these two AWS MCP Servers with the langchain-mcp-adapters. It converts the MCP Server tools into LangChain tools. As RAG system’s integration layer is LangChain this was a great tool for the job.
AWS MCP Servers supported chat has its own window so you can use and test RAG or MCP supported chat responses separately.
Both RAG-supported and MCP-supported chat windows have a Tool Activity drop-down component where you can see which tools were called and what were their responses.
You can also choose the Amazon Nova model you want to use in the chat. Session Info on the sidebar shows basic info about the chat (number of messages, tool calls and total tokens usage).
Amazon Nova Models
The backbone of lumen. I used:
Amazon Nova Micro
Amazon Nova Lite
Amazon Nova Pro
Amazon Nova Micro
A text-only model optimized for very low latency and cost. Has plenty of context token space (128K). My usage of the Micro model in lumen:
summarization
simple tasks (listing quotas, basic info about services)
It is suprisingly good at tool calling and following the system prompt. Needless to say - it’s quite fast!
Amazon Nova Lite
This model can process text, images and videos. Has a larger context token space as well (300K)! My usage of the Lite model in lumen:
cross-referencing multiple sources
somewhat complex queries (how can service X take advantage of service Y, scenario-based questions)
Very solid at tool calling and following the system prompt. Slightly slower than Micro, but still fast.
Amazon Nova Pro
This one has all the benefits of the previous models but bumps things up a notch when it comes to the intelligence. Large context token space (300K) and is really good when it comes to the complex queries. My usage of the Pro model in lumen:
when I need very detailed responses
architecture-based questions (how to do X while having YZ in place, ideas to simplify, lower cost, speed up AWS infrastructure, etc.)
It is rock-solid at tool calling and following the system prompt. It is slower, but it’s worth it. In cases where I expect a very detailed response to a complex query I don’t really mind longer inference time.
I don’t know if this is the case but Nova models seem to be aligned very, very well with AWS Documentation.
Depending on the model-query combination, I didn’t really notice any hallucinations, even when links were included in the response.
It seems Amazon/AWS engineers carefully prepared relevant datasets, which is evident in the models’ performances. In any case - kudos to the team!
Final thoughts
So, building lumen turned out to be a great practical exercise. It definitely helps me dig through AWS docs and it provided real hands-on experience setting up the RAG pipeline, wiring up Qdrant, MCPs and properly testing out the different Amazon Nova models for the job.
Their performance, tool-calling ability and contextual understanding were a highlight.
Of course, there's always room for improvement (PDF parsing, looking at you), maybe refining the chunking strategy or even implementing a custom HTML parser down the line. But for now, lumen is working well as a proof-of-concept and is already a useful tool in my own workflow.
lumen is and will stay open source and MIT licensed.
EDIT 02. June 2025: Quick heads-up on the license: lumen kicked off with an MIT license but to properly mesh with some of the great open-source software lumen uses I'm now switching it over to the GNU Affero General Public License v3.0 (AGPL 3.0). It's just a necessary step to keep things solid and genuinely open for everyone.
There are still some rough edges, so contributions to help smooth them out and build upon the concept are welcome!
You can find the source code and how-to-run instructions here: lumen